이전 글: 2편 — Spring Boot + MyBatis + JWT로 백엔드 기반 잡기
다음 글: 4편 — 7개 외부 API를 어떻게 연결했나
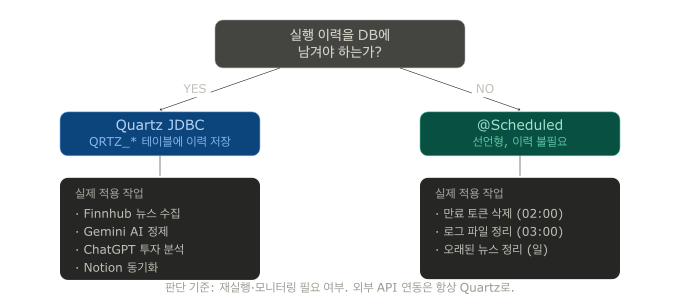
스케줄링을 두 가지 방식으로 나눈 이유
처음에는 하나로 통일하려 했다. @Scheduled로 전부 처리하거나, Quartz로 전부 처리하거나.
그런데 실제로 작업을 분류해보니 요구사항이 완전히 달랐다.
@Scheduled가 맞는 작업
실행 이력을 DB에 남길 필요가 없고, 실패해도 다음 날 재실행하면 그만인 것들이다.
- 새벽 2시 만료 토큰 삭제
- 새벽 3시 로그 파일 정리
- 매주 일요일 오래된 뉴스 데이터 정리
선언이 간결하고, Quartz 테이블을 만들 이유가 없다.
Quartz가 필요한 작업
실행 이력을 QRTZ_* 테이블에 저장해서 "이 Job이 정말 실행됐는가"를 확인해야 하는 것들이다.
- Finnhub / Yahoo RSS 뉴스 수집
- Gemini AI 정제
- ChatGPT 투자 분석
- Notion 동기화
외부 API 장애가 생기면 "어느 단계에서 실패했는지"를 Quartz 이력으로 바로 확인할 수 있다.
모니터링과 재실행이 중요한 작업에서는 Quartz가 분명히 유리하다.
// @Scheduled 예시 — 경량 정리 작업
@Scheduled(cron = "0 0 2 * * *")
public void cleanupExpiredTokens() {
int deleted = refreshTokenMapper.deleteExpired(LocalDateTime.now());
log.info("만료 토큰 {}건 삭제", deleted);
}// Quartz 예시 — 이력이 중요한 Job
@Bean
public Trigger apiCallTrigger() {
return TriggerBuilder.newTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule("0 0 4 * * ?"))
.build();
}
9단계 파이프라인 타임라인
파이프라인은 앞 단계 출력이 뒷 단계 입력이 된다.
각 단계 사이에 여유를 충분히 줘서, 앞 단계가 예상보다 늦게 끝나도 뒷 단계가 빈 데이터를 처리하지 않도록 설계했다.
| 06:20 | MarketIndexService | S&P500, 나스닥, 다우, WTI, 국채 수집 | ~2분 |
| 06:50 | ChatGptService | 전일 예측 결과 vs 실제 주가 평가 | ~5분 |
| 07:00 | NewsCollectService | 보유 종목별 Finnhub + Yahoo RSS | ~15분 |
| 07:20 | NewsCollectService | 글로벌/증시 RSS 수집 | ~5분 |
| 07:35 | NewsCollectService | 테마 키워드 뉴스 | ~5분 |
| 07:40 | GeminiService | 수집 뉴스 전체 AI 정제 | ~30분 |
| 08:30 | ChatGptService | 종목별 BUY/HOLD/SELL 분석 | ~10분 |
| 09:10 | BlogService | 블로그 초안 생성 + 이미지 | ~5분 |
| 09:40 | NotionService | Notion Database 업로드 | ~2분 |
Gemini 정제가 압도적으로 오래 걸린다. 뉴스 한 건당 3초를 대기하는데, 종목 10개에 건당 평균 15건이면 이미 450초(7.5분)다. 글로벌·테마 뉴스까지 더하면 30분을 잡아야 한다. ChatGPT 분석 시작을 08:30으로 여유 있게 설정한 이유다.

파이프라인 의존성 문제와 현재 해결책
이 구조에서 가장 취약한 부분이다.
각 스케줄은 독립적 @Scheduled로 선언되어 있다. 앞 단계가 끝났는지 확인하지 않는다.
Gemini 정제가 예상보다 길어져서 08:30을 넘기면, ChatGPT 분석이 미정제 뉴스를 그대로 사용한다.
실제로 종목이 늘면서 이 상황이 한 번 발생했다.
지금은 스케줄 간격을 넉넉하게 잡아서 시간으로 해결한다.
50분 버퍼를 두고 있는데, 종목이 30개를 넘어가면 이 버퍼로는 감당이 안 된다.
엄밀한 의존성 보장이 필요하다면 Spring Batch의 Job → Step 체인으로 전환이 필요하다.
@Bean
public Job dailyPipelineJob() {
return jobBuilderFactory.get("dailyPipeline")
.start(collectMarketIndexStep())
.next(collectNewsStep())
.next(refineWithGeminiStep())
.next(analyzeWithChatGptStep())
.next(generateBlogStep())
.next(syncToNotionStep())
.build();
}
이렇게 구성하면 앞 단계 완료를 기다린 뒤 다음 단계를 실행한다.
시간이 아닌 완료 신호로 제어하는 구조다.

현재 운영에서는 시간 여유로 충분하지만,
종목 수가 30개 이상으로 늘어나면 이 구조로 전환할 계획이다.
주말 처리와 마지막 거래일 계산
파이프라인은 MON-SAT 기준으로 일요일만 제외하고 실행된다.
토요일에도 실행되는데,
이날은 전날(금요일) 데이터를 기준으로 처리해야 한다.
// 마지막 거래일 계산 (주말 보정)
public LocalDate getLastTradingDate() {
LocalDate today = LocalDate.now();
DayOfWeek dow = today.getDayOfWeek();
if (dow == DayOfWeek.SATURDAY) return today.minusDays(1); // 금요일
if (dow == DayOfWeek.SUNDAY) return today.minusDays(2); // 금요일
return today;
}이 로직이 ChatGptService와 BlogService 양쪽에 중복 구현되어 있다.
공통 DateUtil로 추출해야 하는 기술 부채 중 하나다. 지금 당장 동작은 하지만, 수정할 때 두 곳을 모두 찾아야 한다.
정리
이번 편에서 결정한 것들을 요약하면 다음과 같다.
| 경량 정리 작업 | @Scheduled | 선언 간결, 이력 불필요 |
| 핵심 파이프라인 Job | Quartz JDBC | 실행 이력 확인, 모니터링 필요 |
| 의존성 보장 | 시간 여유(현재) → Spring Batch(예정) | 종목 30개 이상 시 전환 |
| 주말 처리 | 마지막 거래일 보정 로직 | 토요일 실행 시 금요일 기준 처리 |
다음 편에서는 이 파이프라인이 실제로 호출하는 외부 API 7개를 어떻게 연결했는지 다룬다.
Finnhub, Yahoo Finance, FRED, 그리고 AI API들까지 — 별도 클라이언트 라이브러리 없이
Java 내장 HttpClient 하나로 처리한 전략을 기록한다.



